新入生の皆さん、入学おめでとうございます!51代プログラミング研究会のしくがわと申します。 さて、私は主にこのサークルに入ってプログラミングを始めてみたい!って人やプログラミング経験があるのでこのサークルで活かしたい!って人に向けた記事を書いていこうと思います。
皆さんは 恐らく一度は機械学習という言葉を耳にしたことがあると思います。機械学習や人工知能という技術は今、世界中を賑わせており、Googleの開発したゲームAI、「AlphaGo」がプロ棋士を打ち破ったという話は耳に新しいのではないでしょうか?他にも、Googleの自動運転カー等は、ディープラーニングといった技術を利用しています。
ところで、機械学習という技術は確率、統計学といった難解な数学によって確立されているものなのですが、この記事では一切数式を用いずに、概念のみを解説していきます。勿論、難解なソースコードも載せないようにします。
機械学習とは
機械学習というのものは、簡単に説明すれば、「既存のデータに基いて新たなものを予測する」という技術です。身近な例で言えば、顔認識といった技術は、様々な顔写真における顔の特徴をコンピュータに学習させ、新たな顔写真における顔の部分を検出させるといったものです。機械学習の理論自体はかなり昔から存在していたのですが、昔のコンピュータでは理論を実現するだけの計算パワーがありませんでした。また、学習過程で用いられる大規模なデータを取り扱う技術が確立していなかったのです。しかし、近年で飛躍的にコンピュータのパワーが増大し、大規模なデータを処理する技術が確立されたために、この技術が脚光を浴びるようになったのです。
学習方法の分類
機械学習における学習方法には大きく分けて二つの分類があります。「教師あり学習」と「教師なし学習」です。 教師あり学習とは、過去データを入力し、出力された結果を教師データと呼ばれる正解となるデータと比較させ、その誤差を小さくするように入力の過程で与えられる重みと呼ばれるパラメータを更新していくといった学習方法です。教師あり学習で用いられるアルゴリズムは代表的なものに、「単純パーセプトロン」「ナイーブベイズ」「サポートベクトルマシン」「ランダムフォレスト」といった物があります。この中でも特にわかりやすいアルゴリズムである「単純パーセプトロン」「ランダムフォレスト」の解説を後ほどします。解説するアルゴリズムの詳しい所や、解説できなかったアルゴリズムを知りたい人は各自で調べてみてください。きっと世界が広がります。
教師なし学習とは、教師あり学習と違い、教師データを持たない学習法です。主なアルゴリズムにクラスタリングというものがあり、主に凝集型、分割型の二種類があります。
機械学習アルゴリズム
教師あり学習
ここでは主に分類問題に用いられるアルゴリズムを紹介します。分類問題とは、簡単に言えば、受け取ったメールがスパムなのかスパムじゃないのかを判定するような問題です。簡単すぎますね。
単純パーセプトロン
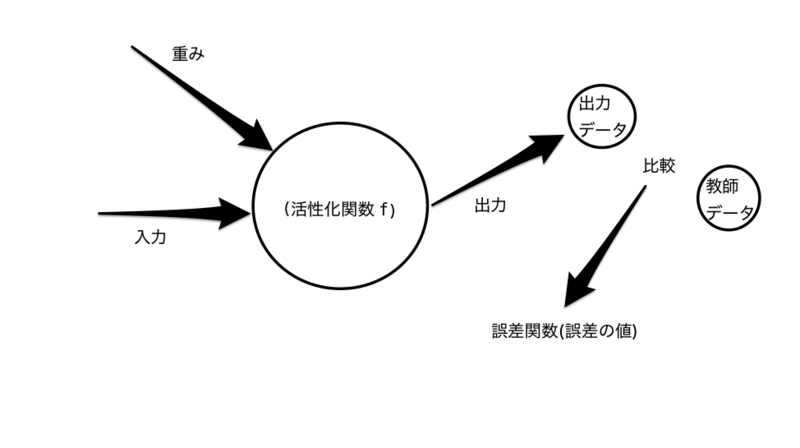 イメージとしては上図のようになります。ベクトルとして与えられる入力データに重みがかけあわされ、その線形結合和の値に応じて0,1いずれかの数値が出力データとして与えられます。その出力データと教師データを比較し、誤差を誤差関数として与えます。一連の操作を誤差が出来るだけ小さくなるまで繰り返します。これが、単純パーセプトロンのアルゴリズムになります。
層において、線形結合和に活性化関数と呼ばれる関数が適用される場合があります。この時、出力値が0か1ではなく、確率値が与えられたりすることもあります。
イメージとしては上図のようになります。ベクトルとして与えられる入力データに重みがかけあわされ、その線形結合和の値に応じて0,1いずれかの数値が出力データとして与えられます。その出力データと教師データを比較し、誤差を誤差関数として与えます。一連の操作を誤差が出来るだけ小さくなるまで繰り返します。これが、単純パーセプトロンのアルゴリズムになります。
層において、線形結合和に活性化関数と呼ばれる関数が適用される場合があります。この時、出力値が0か1ではなく、確率値が与えられたりすることもあります。
単純パーセプトロンの階層を大きくしたものはニューラルネットワークと呼ばれ、ディープラーニングの礎になっている技術です。下の図は3層のニューラルネットワークです。
 ニューラルネットワークにおける学習法としては、確率的勾配降下法やAdam, AdaGradといったものが有名なのですが、これらの詳細はここには書かないのでググってみて下さい。
この単純なニューラルネットワークに改良を施したものが、畳込みニューラルネットワーク(CNN)だったり、再帰型ニューラルネットワーク(RNN)だったりします。これらを用いることで画像認識、自然言語処理といった単純なニューラルネットワークでは難しい機械学習を行うことができます。詳しく知りたい方々はググってみるなり図書館で調べてみましょう。
ニューラルネットワークにおける学習法としては、確率的勾配降下法やAdam, AdaGradといったものが有名なのですが、これらの詳細はここには書かないのでググってみて下さい。
この単純なニューラルネットワークに改良を施したものが、畳込みニューラルネットワーク(CNN)だったり、再帰型ニューラルネットワーク(RNN)だったりします。これらを用いることで画像認識、自然言語処理といった単純なニューラルネットワークでは難しい機械学習を行うことができます。詳しく知りたい方々はググってみるなり図書館で調べてみましょう。
ランダムフォレスト
 ランダムフォレストとは、決定木と呼ばれるノードとリンクで構成されたネットワークをたくさん用いることで実現するアルゴリズムになります。決定木単体では学習を行っても高い精度を出せない為に、決定木をたくさん用いることで精度を高めていこうという考えに基いています。こういった考えに基づく学習方法は集団学習と呼ばれています。このアルゴリズムは簡単ながら、高精度の結果が得られることで有名です。
ランダムフォレストとは、決定木と呼ばれるノードとリンクで構成されたネットワークをたくさん用いることで実現するアルゴリズムになります。決定木単体では学習を行っても高い精度を出せない為に、決定木をたくさん用いることで精度を高めていこうという考えに基いています。こういった考えに基づく学習方法は集団学習と呼ばれています。このアルゴリズムは簡単ながら、高精度の結果が得られることで有名です。
サポートベクトルマシン(SVM)
サポートベクトルマシンは、データ間の境界線を「マージン最大化」と呼ばれる手法で求めるアルゴリズムです。マージン最大化とは、「異なる種類のデータの集団から最も遠くなる境界線を選択する」というものです。マージン最大化によって分類されたものは汎化能力が高いという特徴があります。
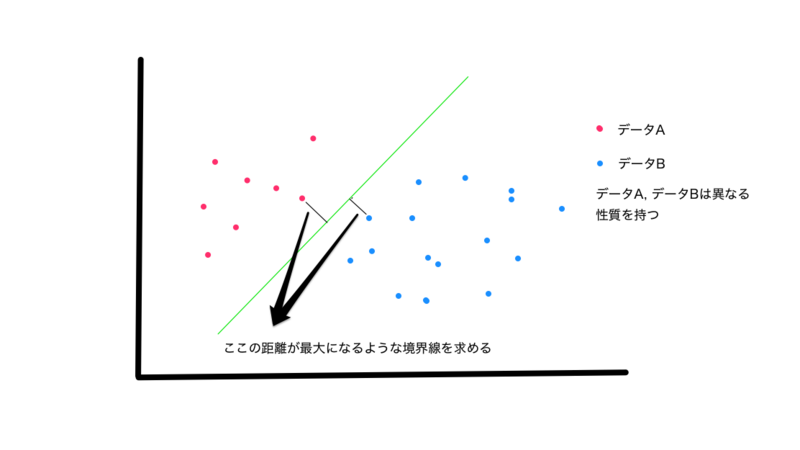 単純パーセプトロンなどは、限られた問題を解くことしかできないのですが、このアルゴリズムでは「カーネル法」と呼ばれる方法を用いることで、様々な問題に対処できるようになっており、非常に重要なアルゴリズムになっています。
単純パーセプトロンなどは、限られた問題を解くことしかできないのですが、このアルゴリズムでは「カーネル法」と呼ばれる方法を用いることで、様々な問題に対処できるようになっており、非常に重要なアルゴリズムになっています。
教師なし学習
凝集型クラスタリング
凝集型クラスタリングとは、「似ているものを集める」方法です。各データの類似度を計算して、クラスタと呼ばれる集合を形成します。クラスタの性質はデータが分類されてから知ることが出来ます。
分割型クラスタリング
分割型クラスタリングとは、「似ていないものとの境界を作る」方法です。主に、k-平均法(k-means)という手法が用いられます。
まとめ
いくつかの機械学習のアルゴリズムを紹介しましたが、これらのアルゴリズムを実装するのは非常に大変です。ですので、これらのアルゴリズムを実装しなくても済むように、様々な機械学習用のライブラリが提供されています。代表的なものに、「Tensorflow」「Scikit-learn」「Caffe」「Chainer」などがあります。これらのライブラリは基本的にPython,C++向けに提供されています。
総括
機械学習や人工知能といった分野は今、最もホットな分野で日々世界中の研究者達によって研究されています。いつの日か、人工知能が人間の頭脳に追いつく、または越える日がやってくるかもしれませんね。
 この記事を通して少しでも機械学習といった分野に興味を持ってもらえれば嬉しいです。このサークルでは統計班でこのようなことをやっています。是非来てください!
この記事を通して少しでも機械学習といった分野に興味を持ってもらえれば嬉しいです。このサークルでは統計班でこのようなことをやっています。是非来てください!